PHIDEMOBP Demo_Invoice_PreQuery
Program PHIDEMOBP Demo_Invoice_PreQuery is called by demo report "Invoice Form". The program reads command line parameters and builds the data blob stored in file "TMP". Non blob data is returned to the report via the USERDATA common variable.
The named COMMON defined at the beginning of the program is required to pass data between the program and phiReport.
Line 8 reads the command line parameter generated by the Pre-Query Process call.

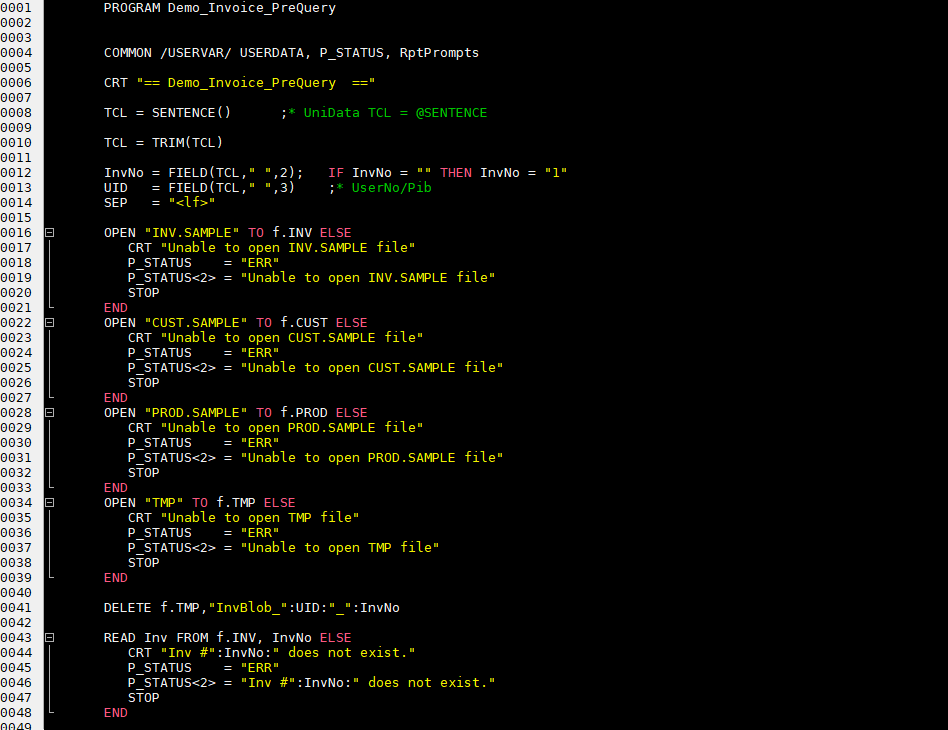
Error messages are returned via the P_STATUS common variable. If P_STATUS<1> = "ERR" phiReport will display the error message in P-STATUS<2> and stops processing the report.
After reading the Invoice item, the program extracts the header information and builds the table of value pairs in variable USERDATA. The first sub-value of each value must match a named shape or named cell on the Excel template. If the same name is used more than once, only the last occurrence will be used. If a name does not match any named shape/cell it will be ignored.
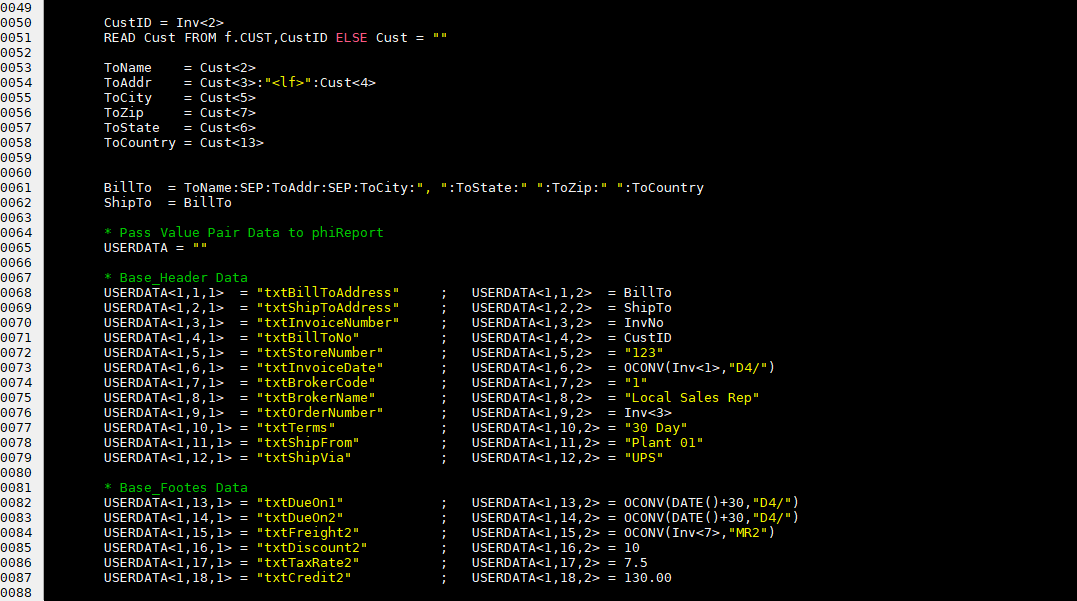
Line items in the report body are build as part of the data blob. The structure of the blob should match the number of columns defined in the Excel template where each column corresponds to a value.
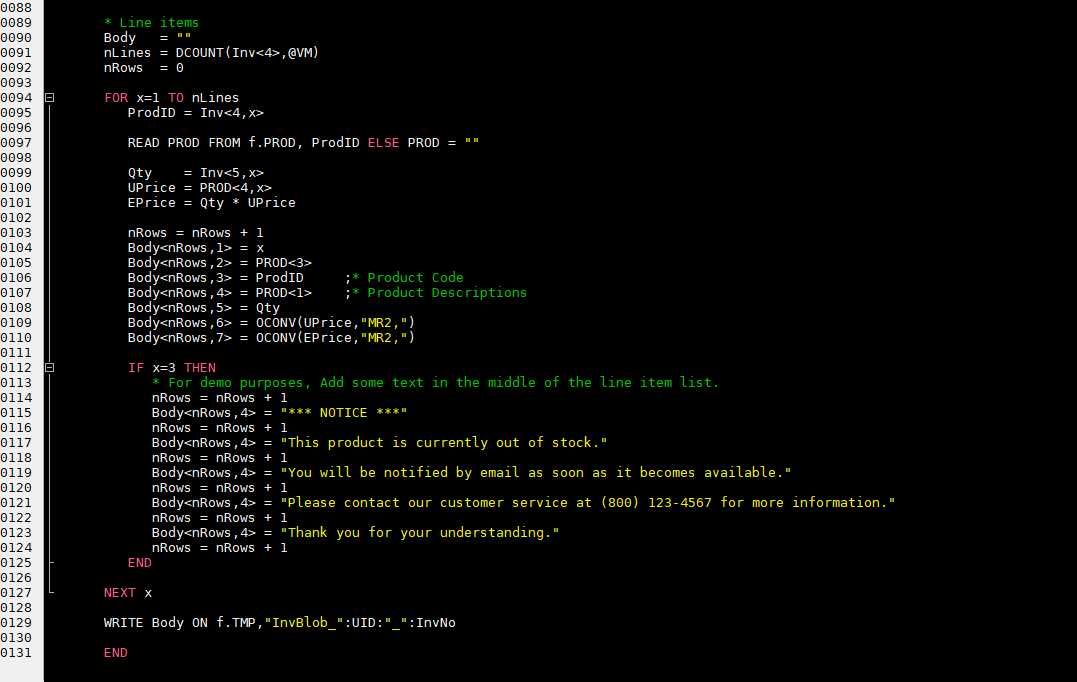
A non-data blob output is generated by a query statement and is restricted to columnar type outputs. The data blob gives us more control over what to output and where and even though our template defines 7 columns, our data blob does not have to provide 7 columns of data. With the data blob we can also dynamically output a variable number of columns from one row to the next.
In our example program, lines 112-125 skips columns 1, 2 and 3 and puts data in column 4. Columns 5, 6 and 7 are left empty to allow the data in column 4 to "bleed" out of its cell.
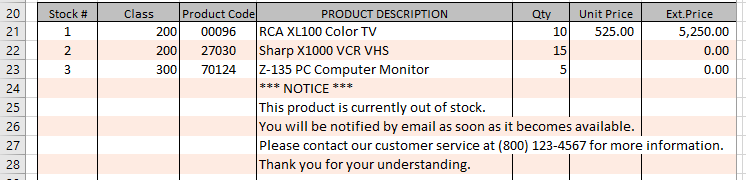
Once the body data is created it is saved in file TMP. The Item Id used is important because it will be used by the query engine to "SELECT" against. In report definition, we need to create query a statement to retrieve all the blobs required for the report.

It is possible to create a multi-page blob by creating multiple blob items. In this case, we need to make sure that the select statement used to retrieve the blobs can return them in the correct order.
Note: If a report requires a lot of data, it is recommended to create multiple smaller data blobs vs one large data blob. Data blobs are downloaded in one chunk of data which can create performance issues. By default, phiReport downloads non-blob data in packets of about 100k. Blob data greater than 100k should be split into smaller blobs. phiReport does not split data blobs.